

.svg)

.svg)

.svg)

.svg)


.png)
.jpg)


.svg)

.png)


.png)

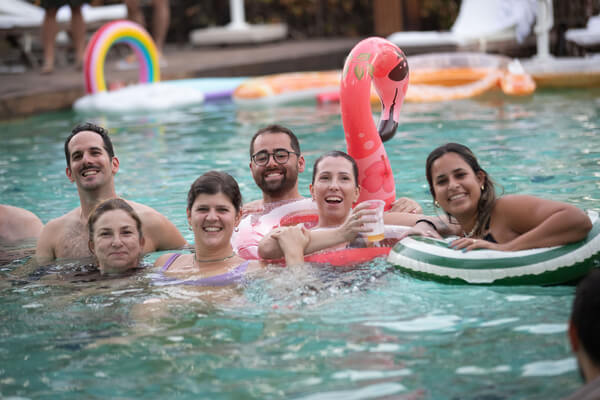
Careers
Want to join our amazing team?
GRC is changing fast! and we’re helping lead that change.
At Anecdotes, you’ll work with smart, driven people solving real problems for modern companies around the world.
We move fast, take ownership seriously, and believe great work happens in teams that genuinely enjoy building together.
At Anecdotes, you’ll work with smart, driven people solving real problems for modern companies around the world.
We move fast, take ownership seriously, and believe great work happens in teams that genuinely enjoy building together.
If you’re looking to grow quickly, make real impact, and be part of a team that cares deeply about what it builds; we’d love to meet you!
Our Values
We aspire to build a company where culture is intentional, processes are meaningful, and every team member is empowered to perform, grow, and make real impact.
Our open roles
Take a look at our open positions
Tel Aviv
Come for the challenge.
Stay for the people.
Work closely with smart, thoughtful teammates who care deeply about what they build and how they build it.
.png)

%202.png)

.png)



%201.png)
Didn’t find what you are looking for?
We would love to hear from you
Contact us at: careers@anecdotes.ai
Follow us on
.svg)
.svg)










© All rights reserved to Anecdotes A.I Ltd, 2026